1. 모든 속성을 만족할 수 없다는 CAP 이론
가. CAP(Consistency, Availability, Partitioning)이론이란?
- 2002년 버클리 대학의 Eric Brewer 교수에 의해서 발표된 분산 컴퓨팅 이론으로, 분산 컴퓨팅 환경은 Consistency, Availability, Partitioning 3가지 특징을 가지고 있으며, 이중 두 가지만 만족할 수 있다는 (Pick two) 이론
- 분산 컴퓨팅 시스템이 보장해야 할 3가지 특징(일관성,가용성,부분 결함허용)을 정의하고,분산 시스템은 3가지 중 2가지만 보장할 수 있고(Pick two), 3가지 모두를 보장하는 것은 불가능 하다는 이론
| CAP 이론 모형 | C·A·P | 설명 |
 |
Consistency (일관성) | - 모든 사용자는 동시에 항상 같은 데 이터를 조회 한다 |
| Availability (가용성) | - 모든 사용자는 항상 read/write 할 수 있다 - 몇몇 노드 장애 시에도 다른 노드들은 작동해야 한다 |
|
| Partition Tolerance (부분 결함허용) | - 물리적 네트워크 분할(Partition)에도 시스템은 정상 동작 해야 한다 |
|
| Pick Two | - CAP중 2가지만 선택 가능 |
2. CAP 이론 측면에서 RDB와 NoSQL DB
가. CAP 이론과 DBMS의 관계
- 트위터와 같이 하루에 올라가는 수천만 건의 글을 감당할 수 있는 분산형 데이터베이스가 필요 하면서, ROI높고 성능 좋은 DBMS 필요
- 일반적으로 NoSQL시스템은 관계형을 포기하거나 트랜잭션 구조를 느슨하게 함으로써 수평 확장이 가능하도록 하는데 주요 목적을 가짐
| DBMS | 설명 | 적용 사례 |
| RDB | - Consistency + Availability 선택 | - 금융 서비스: 미션 크리티컬한 트랜잭션 보장 |
| NoSQL DB | - Consistency + Availability 포기 - 분산 확장성을 보장 - 트랜잭션 ACID를 느슨하게 유지 |
- C + P 형: 대용량 분산파일시스템 à 성능 보장형 (Bigtable, Hypertable, Hbase - A + P 형: 비동기식 서비스, SNS 서비스 (Dynamo: Amazon, Apache Cassandra: Twitter |
- NoSQL DB 제품은 CAP 중에서 C 또는 A를 일부 포기함으로써 분산 확장을 택함
나. CAP 이론 측면에서 RDB와 NoSQL DB 비교
| 구분 | RDB | NoSQL |
| 특징 | - JOIN - ACID 트랜잭션 - 고정된 스키마 |
- Update/Delete 잘 사용되지 않음 -> Insert로 대체 - 강한 Consistency 불 필요 - 노드의 추가/삭제, 데이터 분산에 유연 - 모델링(Key-value, 계층형/그래프 데이터 등) - Query 유연 |
| 장단점 | - 데이터 무결성, 정합성 보장 - 정규화된 Table, 작은 크기의 트랜잭션 |
- Web 환경의 다양한 정보 검색 및 저장에 강함 |
| 단점 | - 확장성 한계 - 클라우드 분산 환경에 적합하지 않음 |
- 데이터 무결성, 정합성 보장하지 않음 |
3. 클라우드 컴퓨팅 환경에서 NoSQL DB 필요성 (RDB 제약)
가. NoSQL DB(Not Only SQL DB)의 개념
- 관계 데이터베이스(RDB) 한계를 극복하기 위해, Join이 없고, 고정된 스키마를 갖지 않는 새로운 형태의 데이터 저장소
나. 클라우드 환경에서 NoSQL DB 필요성(RDB 제약)
- 클라우드 컴퓨팅/웹 환경의 대량의 데이터를 저비용으로 처리할 수 있는 DB 필요
- 네트워크 발전으로 인해 발생하는 많은 양의 데이터를 처리하기 위해 클라우드 컴퓨팅 등 분산 처리 시스템이 도입되면서 기존 RDB의 확장성 한계로 인해 NoSQL DB가 대안으로 대두되고 있음
'1. IT Story > Basic Studies' 카테고리의 다른 글
| 데이터 품질관리의 Data Profiling (0) | 2020.12.24 |
|---|---|
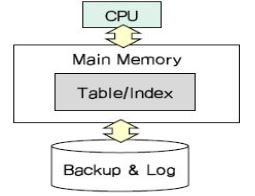
| MMDB(Main Memory Data Base) (0) | 2020.12.24 |
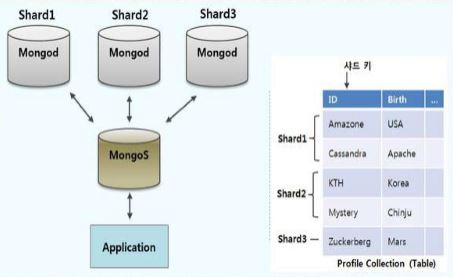
| DB 샤딩(Sharding) (0) | 2020.12.24 |
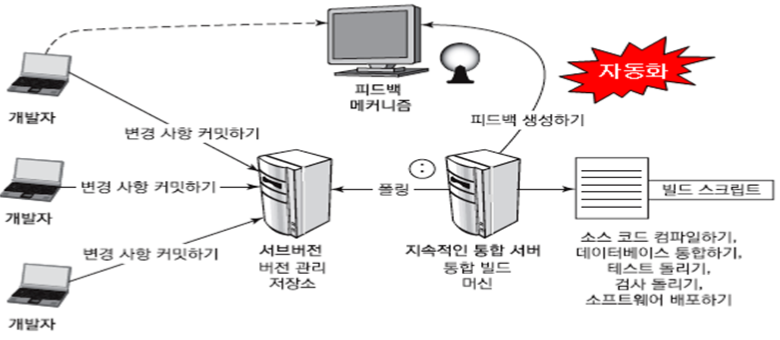
| CI(Continuous Integration) (0) | 2019.11.21 |
| 테스트자동화 (0) | 2019.09.22 |
| V&V(Verification & Validation) (0) | 2019.09.20 |
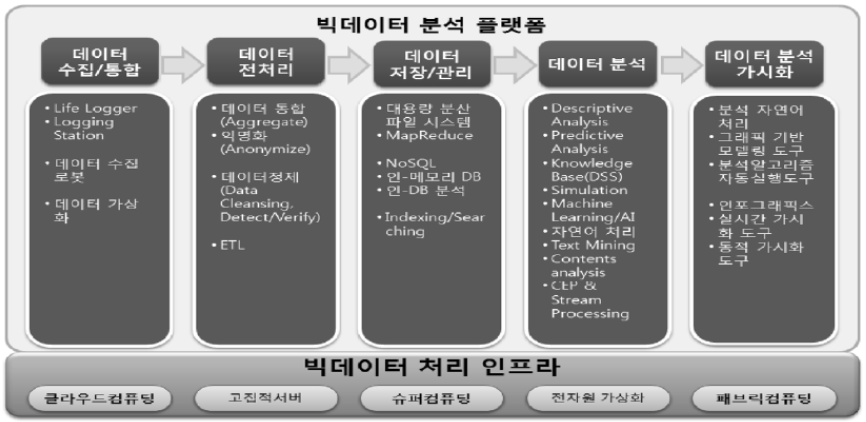
| 빅데이터(Big Data) (0) | 2019.09.19 |
| 3D프린팅 (0) | 2019.09.17 |

운명을바꾸는자
IT와 함께 살아가는 삶